4 Jun 2026
Charting Interconnect Bandwidth Allocations Across Multi-GPU Setups for Consistent Data Exchange in Large-Scale Simulation Environments
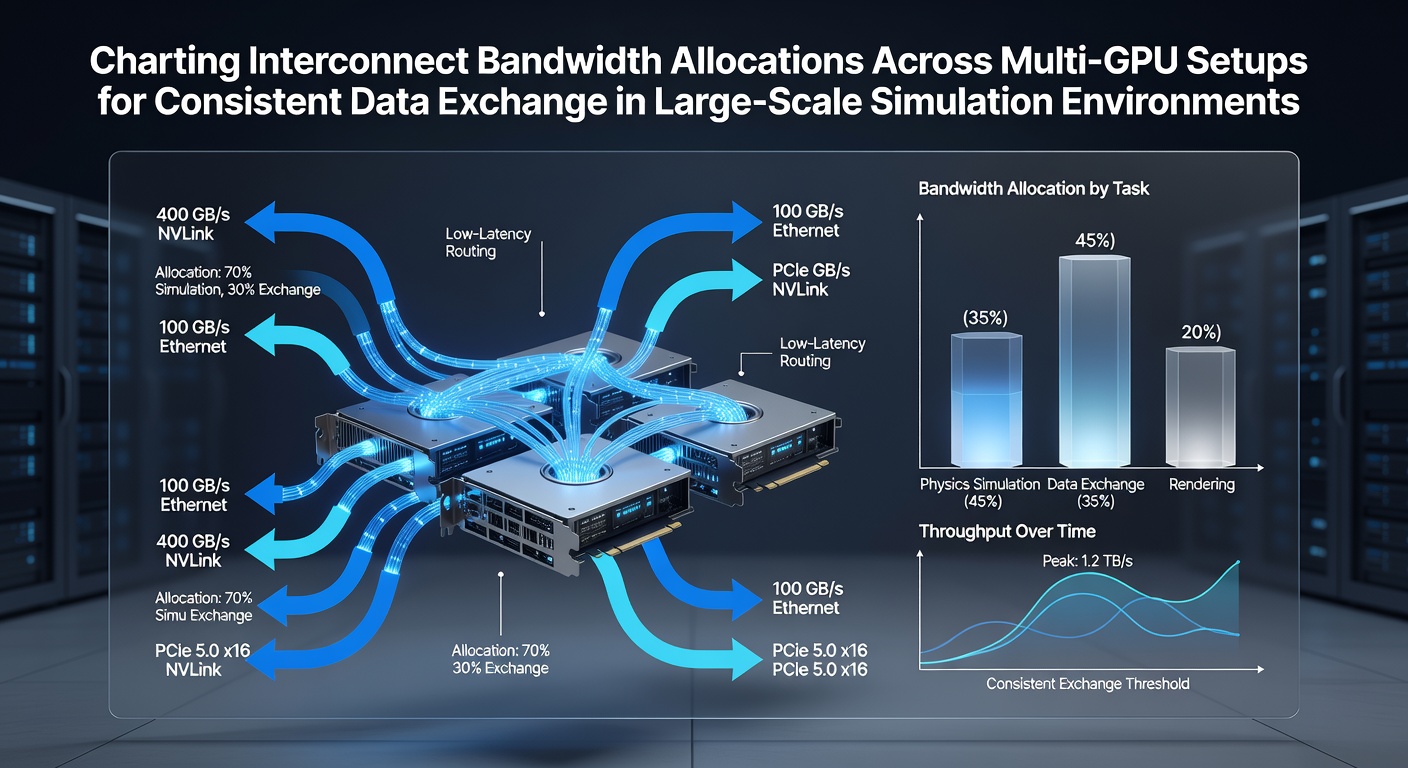 Researchers track interconnect bandwidth allocations in multi-GPU configurations to maintain steady data movement during demanding simulation workloads, and this process relies on mapping traffic patterns across NVLink fabrics, PCIe lanes, and high-speed networking fabrics like InfiniBand. Data centers running computational fluid dynamics or molecular dynamics codes distribute GPU-to-GPU transfers so that each node receives predictable latency and throughput, which prevents bottlenecks when thousands of GPUs exchange partial results every iteration. Hardware vendors publish measured bidirectional bandwidth figures for their interconnects, and these numbers guide allocation decisions in production clusters. For instance, NVIDIA's NVLink implementations deliver up to 900 GB/s aggregate bandwidth between paired GPUs in recent generations, while PCIe 5.0 links top out at 128 GB/s per direction when fully utilized. System architects combine these specifications with application profiling tools to decide how many lanes or links to dedicate to each communication path.
Researchers track interconnect bandwidth allocations in multi-GPU configurations to maintain steady data movement during demanding simulation workloads, and this process relies on mapping traffic patterns across NVLink fabrics, PCIe lanes, and high-speed networking fabrics like InfiniBand. Data centers running computational fluid dynamics or molecular dynamics codes distribute GPU-to-GPU transfers so that each node receives predictable latency and throughput, which prevents bottlenecks when thousands of GPUs exchange partial results every iteration. Hardware vendors publish measured bidirectional bandwidth figures for their interconnects, and these numbers guide allocation decisions in production clusters. For instance, NVIDIA's NVLink implementations deliver up to 900 GB/s aggregate bandwidth between paired GPUs in recent generations, while PCIe 5.0 links top out at 128 GB/s per direction when fully utilized. System architects combine these specifications with application profiling tools to decide how many lanes or links to dedicate to each communication path.Mapping Traffic Patterns in Production Clusters
Simulation codes often follow a halo-exchange pattern where boundary data moves between neighboring GPUs, adn administrators allocate dedicated bandwidth slices to these messages so they complete before the next computation phase begins. Profiling frameworks record message sizes and frequencies across runs, then feed the statistics into scheduling software that reserves portions of the interconnect fabric accordingly.
Observational studies from large installations show that uneven allocation quickly leads to stragglers, where some GPUs wait on data while others sit idle. Teams therefore apply weighted round-robin or credit-based schemes that adjust shares dynamically based on instantaneous queue depths.
Technologies Driving Allocation Decisions
NVLink switches allow finer-grained partitioning than traditional PCIe switches because they expose multiple virtual channels that can be prioritized separately. In contrast, InfiniBand fabrics rely on quality-of-service classes defined at the subnet manager level, which system operators configure to match the communication graph of each simulation job.

Researchers at institutions such as those contributing to the NVIDIA GTC proceedings have documented how combining NVLink domains with InfiniBand reduces cross-traffic interference. The same reports note that PCIe-only setups require careful lane bifurcation to avoid saturating root-complex resources when eight or more GPUs share a single host.
Allocation Algorithms and Their Measured Impact
Static allocation tables work well for regular grid decompositions common in weather or seismic modeling codes, whereas dynamic algorithms based on reinforcement learning adjust shares every few seconds when workloads shift toward collective operations like all-reduce. Benchmarks published by supercomputing centers indicate that dynamic methods cut average job completion time by measurable percentages when communication phases vary across iterations.
One documented approach assigns higher priority to small control messages that synchronize global timesteps, while bulk data transfers receive the remaining capacity. This separation prevents latency-sensitive barriers from queuing behind megabyte-scale payloads.
Scaling Considerations for Exascale Environments
As node counts climb into the tens of thousands, the diameter of the interconnect fabric grows and cumulative hop latency becomes a factor. Allocation schemes therefore incorporate topology awareness, placing communicating GPU pairs on the same switch or rail whenever possible. Data from the U.S. Department of Energy's exascale projects shows that topology-aware placement combined with bandwidth reservation improves strong-scaling efficiency in codes that previously plateaued around 50 percent parallel efficiency.
European research consortia have explored similar techniques on systems using AMD Instinct GPUs and Infinity Fabric links, confirming that the same principles transfer across vendor ecosystems when measurement tools expose comparable counters.
Conclusion
Consistent data exchange in large-scale GPU simulations depends on deliberate bandwidth allocation across heterogeneous interconnects. Profiling data, topology maps, and adaptive reservation mechanisms together enable operators to keep utilization high while meeting the latency targets required by tightly coupled codes. Continued refinement of these methods tracks hardware advances and evolving application communication patterns.