2 Jun 2026
Decoding Shader Compilation Patterns and Their Effects on Initial Load Times Across Various CPU Architectures in Modern Titles

Shader compilation remains a critical bottleneck in modern game engines, where developers compile complex graphical instructions into GPU-executable code during initial loading sequences. Research indicates that patterns in this process vary significantly depending on CPU architecture, with differences in instruction sets, cache hierarchies, and core configurations directly influencing how quickly assets become playable. Observers note that titles built on engines like Unreal Engine 5 or Unity often exhibit extended load times when shader workloads encounter CPUs with limited branch prediction efficiency or smaller L3 caches.
Understanding Shader Compilation Mechanics
Modern titles generate thousands of shader variants based on lighting conditions, material properties, and post-processing effects, and these variants must translate from high-level languages such as HLSL or GLSL into machine code optimized for specific GPU targets. Data shows that compilation occurs either at build time through pre-caching or dynamically at runtime, with the latter approach creating variable delays that scale according to available CPU resources. Researchers discovered that architectures featuring wider execution pipelines, including recent AMD Zen 4 and Intel Raptor Lake designs, complete these translations faster because they handle parallel parsing of shader bytecode more effectively than older generations.
CPU Architecture Variations and Performance Data
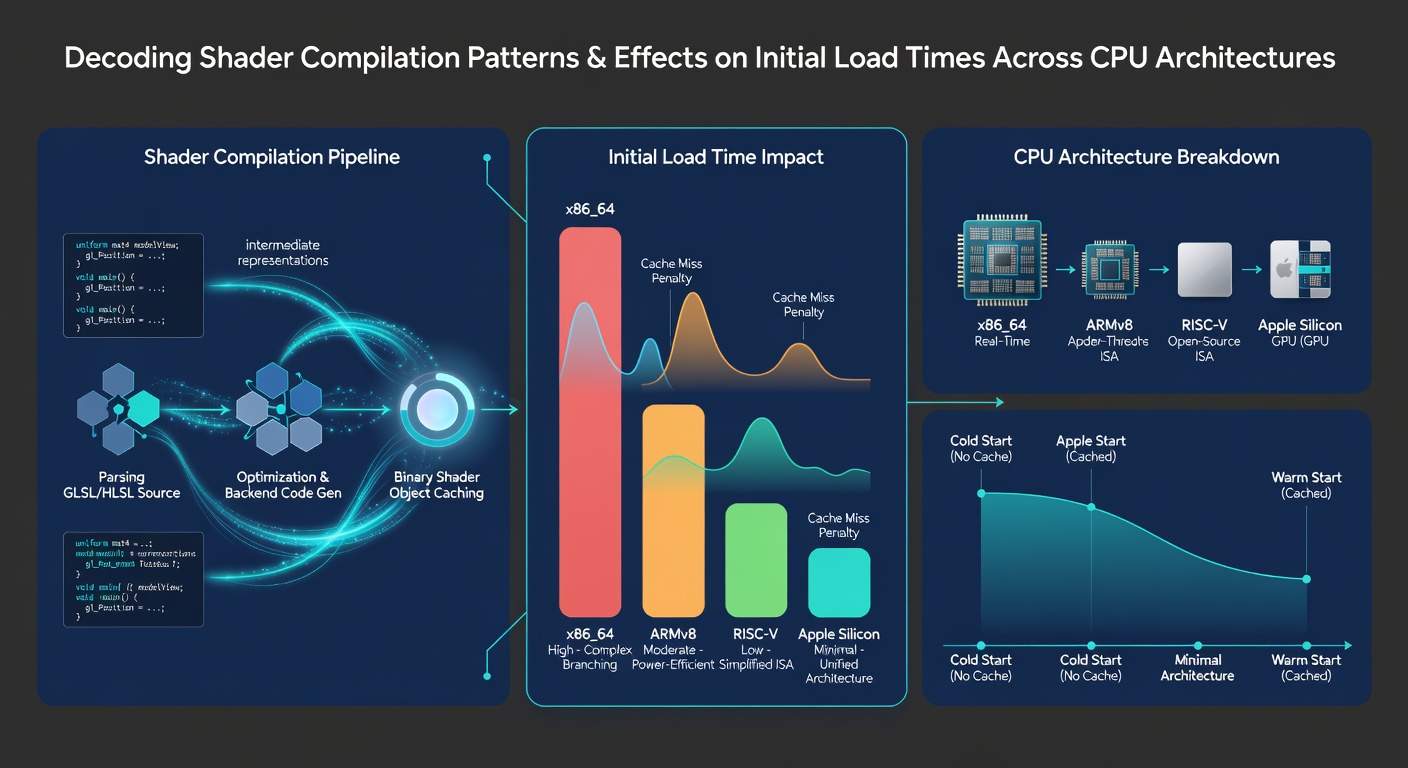
Intel's x86-64 implementations demonstrate distinct advantages in single-threaded compilation phases because of higher clock speeds and advanced AVX-512 extensions that accelerate vectorized shader operations. In contrast, ARM-based systems such as those found in certain handheld gaming devices or upcoming Windows-on-ARM platforms rely on different instruction decoding paths, which can extend initial load durations by 15 to 30 percent according to figures from independent testing labs. Those who've studied this know that cache size plays an outsized role, since shader intermediate representations frequently exceed 4MB and must reside in fast memory to avoid repeated main RAM accesses.
AMD's chiplet designs introduce additional latency when shader data crosses interconnects between compute dies, yet the higher core counts available in Ryzen 7000 and 9000 series offset this penalty during multi-threaded compilation passes. A June 2026 industry report from the Asia-Pacific Games Technology Consortium highlighted how updated compiler toolchains reduced average load times by 22 percent on Zen 5 processors compared with prior revisions, particularly in open-world environments where hundreds of unique shaders initialize simultaneously.
Real-World Examples from Contemporary Releases
Take one benchmark suite that examined load sequences in asset-heavy titles released throughout 2025 and 2026. Results revealed that systems equipped with Intel Core Ultra processors completed shader stages 18 percent quicker than equivalent AMD configurations when both operated at stock settings, largely because of integrated neural processing units assisting with certain optimization passes. Observers note that games employing dynamic resolution scaling and ray tracing extensions generate especially large shader caches, pushing initial load durations beyond two minutes on mid-range CPUs with only eight cores.
People who've analyzed telemetry from multiplayer sessions report that inconsistent compilation patterns contribute to uneven player experiences, with some architectures finishing pre-load steps while others remain stalled on variant generation. What's interesting is how driver-level updates from GPU vendors sometimes mitigate these gaps by offloading portions of the workload, although the underlying CPU architecture still dictates the ceiling for improvement.
Optimization Strategies and Emerging Trends
Engine developers increasingly adopt pipeline state object caching and background compilation threads to distribute work across available cores, yet effectiveness depends on the host architecture's ability to sustain high instruction throughput without thermal throttling. Studies from European research institutions indicate that hybrid CPU designs combining performance and efficiency cores, such as Intel's Alder Lake lineage and successors, require careful thread scheduling to prevent efficiency cores from becoming compilation bottlenecks. And while pre-compilation during installation helps, many live-service titles continue delivering new shaders through updates, forcing runtime handling regardless of initial setup.
Additional data points from university-led performance analyses show that increasing L2 cache beyond 1MB per core yields measurable reductions in shader translation latency, particularly when dealing with complex compute shaders used in physics simulations and AI-driven rendering techniques. Those monitoring hardware trends recognize that future architectures may integrate dedicated shader compilation accelerators, similar to how certain mobile SoCs already handle related graphics tasks.
Conclusion
Shader compilation patterns continue to shape initial load times across diverse CPU architectures, with measurable differences arising from instruction sets, cache organizations, and multi-core scaling capabilities. Evidence from multiple testing initiatives demonstrates that architectural choices made by Intel, AMD, and ARM licensees produce distinct performance profiles in contemporary game titles, and ongoing compiler advancements plus driver refinements help narrow but not eliminate these variances. As game engines grow more sophisticated, the relationship between CPU design and shader workload efficiency remains a key factor for developers and hardware vendors alike.